Sempre più spesso si sente parlare di web3, in relazione alle blockchain (Ethereum in particolare), agli smart contract e al metaverso.
La confusione è molta, tra chi parla di web3 come del futuro del web, chi abusa dell’espressione DApp e chi invece ridimensiona il tutto (Elon Musk[1], per dirne uno), vedendo il termine web3 più che altro come una buzzword.
Cerchiamo quindi di fare ordine, spiegando cosa significano espressioni come web3, web 3.0 e DApp.
In questa lezione ripercorreremo la storia del Web, in modo da comprendere meglio cosa sia il web3 e quale sia, almeno nelle intenzioni, la sua portata innovativa.
1- Internet e web
Chiariamo subito un punto fondamentale: il web e internet sono due cose diverse, non sono sinonimi.
Internet è un sistema globale di reti di computer interconnesse tra loro, mediante l’utilizzo di un set di protocolli.
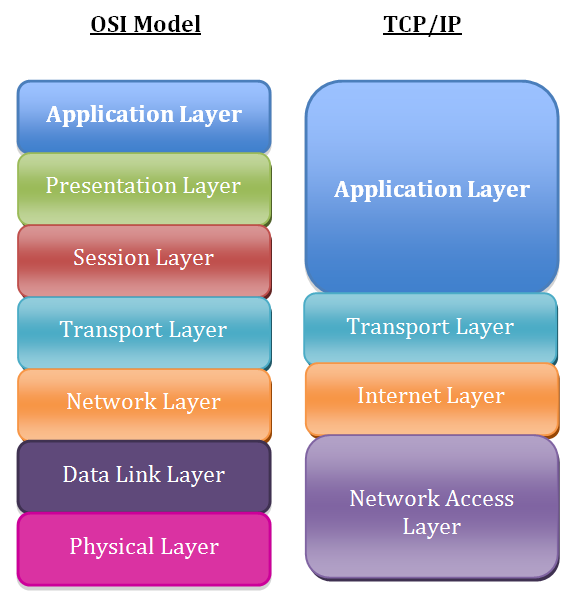
In informatica si è soliti utilizzare un modello concettuale per descrivere i sistemi di telecomunicazioni, si tratta del modello OSI (Open Systems Interconnection)[2], stabilito nel 1984 dalla ISO (International Organization for Standardization)[3], uno tra i maggiori enti di standardizzazione internazionale.
Il modello OSI stabilisce degli standard per l’architettura logica di una rete, attraverso una struttura composta da sette strati o livelli (in inglese “layers”) che seguono un ordine gerarchico.
Senza scendere nei dettagli, basti sapere che ogni layer utilizza un set di protocolli di comunicazione.
Un protocollo di comunicazione non è nient’altro che un insieme di regole stabilite formalmente che regolano le modalità di comunicazione tra delle entità.
Pensiamo, per esempio, a quando rispondiamo a una chiamata e diciamo “Pronto, chi parla?”. Possiamo vederlo come un’estrema semplificazione di un protocollo di comunicazione.
Dicendo questa frase, facciamo capire all’interlocutore che abbiamo risposto alla chiamata e che siamo pronti a iniziare la conversazione.
Allo stesso modo, le varie entità che costituiscono una rete, hanno bisogno di regole che definiscano inequivocabilmente il modo in cui comunicano tra loro.
| Layer | Nome | Protocolli |
|---|---|---|
| 7 | Application Layer | HTTP, FTP, DNS, SNMP, Telnet |
| 6 | Presentation Layer | SSL, TLS |
| 5 | Session Layer | NetBIOS, PPT |
| 4 | Transport Layer | TCP, UDP |
| 3 | Network Layer | IP, ARP, ICMP, IPSec |
| 2 | Data Link Layer | PPP, ATM, Ethernet |
| 1 | Physical Layer | Ethernet, USB, Bluetooth, IEEE802.11 |
Nel modello OSI abbiamo quindi 7 layer, in ognuno dei quali vengono usati dei protocolli specifici.
Un altro modello comunemente usato è l’Internet protocol suite[4], più comunemente noto come modello TCP/IP, molto simile al modello OSI, con la differenza che i tre livelli più alti vengono appiattiti in un unico layer, così come i due livelli più bassi:
Con World Wide Web (abbreviato Web), intendiamo uno dei principali servizi di internet.
Il web è basato sul protocollo HTTP (Hypertext Transfer Protocol)[5] che, come vediamo, si trova nell’Application Layer del modello OSI, insieme ad altri protocolli molto noti come l’FTP (File Transfer Protocol), utilizzato per inviare e ricevere file a/da altri sistemi, o ai protocolli utilizzati per la posta elettronica.
Nell’Application Layer troviamo dunque, come suggerisce il nome, diverse applicazioni di internet, una delle quali è il web.

2- Storia di internet e del web
Fatta questa fondamentale distinzione tra internet e web, ripercorriamo velocemente la storia di quest’ultimo che, ovviamente, è intrecciata a quella di internet.
La storia di internet si spinge molto più indietro nel tempo rispetto a quella del web.
Negli anni ’60, in piena guerra fredda, la DARPA[6] (agenzia del Dipartimento della Difesa degli Stati Uniti che si occupa dello sviluppo di tecnologie a uso militare) ideò una rete di computer che vide la sua concretizzazione pratica nel 1969, col nome di ARPAnet[7].
ARPAnet, antenato dell’internet che tutti conosciamo, fu quindi sviluppata per scopi militari e in seguito iniziò a svilupparsi anche in ambito universitario.
Già nella seconda metà degli anni ’70 iniziò a essere usata la parola internet e con la standardizzazione dell’Internet Protocol Suite, nel 1982, il numero di reti interconnesse iniziò a crescere.
Nel 1983 quello che ormai era diventato a tutti gli effetti l’internet di oggi, aveva totalmente perso lo scopo militare iniziale, motivo per il quale la sezione militare si isolò e nacque MILNET[8] che, a sua volta, negli anni ’90, diventò NIPRNET[9].
Una volta separatosi dalla MILNET, dunque, internet proseguì per la sua strada che ci porta fino a oggi.
Parallelamente allo sviluppo di internet, negli anni ’80, si stavano preparando le condizioni per la nascita del World Wide Web.

La nascita del web è strettamente legata a Tim Berners-Lee, informatico inglese classe 1955.
Lee mise insieme concetti e tecnologie già esistenti:
- Internet e i protocolli TCP/IP
- Il concetto di ipertesto = un insieme di documenti collegati tra di loro attraverso parole chiave che consentono una lettura non lineare, ovvero di saltare da un documento all’altro seguendo i link[10].
Nel 1980, mentre lavorava al CERN di Ginevra, realizzò ENQUIRE[11], un semplice software basato sugli ipertesti, una sorta di antenato del web, che non ebbe la sua stessa fortuna.
Intanto, col diffondersi di internet, nel corso degli anni ’80, in molti si rendevano conto della necessità di avere un sistema per trovare e organizzare le informazioni sparse tra la rete.
Nacque così, nel 1985, il Domain Name System (DNS)[12], il sistema attraverso il quale sono identificati e nominati i nodi della rete.
Continuando a lavorare sul suo progetto, Lee arrivò a una prima proposta concreta nel 1989, con un documento chiamato Information Management: A Proposal[13].
Il sistema proposto si chiamava ancora Mesh, anche se già veniva usata la parola “web”.
Lee e il suo team svilupparono il set di strumenti di cui tuttora il Web fa uso, come ad esempio l’idea di URI (Universal Resource Identifier)[14], il protocollo HTTP (che abbiamo già incontrato nel modello ISO) e il linguaggio di markup HTML[15], inoltre diedero vita al primo web browser, chiamato WorldWideWeb, al primo web server e al primo sito[16].
Nel 1994 Lee fondò il World Wide Web Consortium (W3C)[17], organizzazione non governativa che è stata, ed è tuttora, fondamentale per lo sviluppo del web, stabilendo degli standard e cercando di fornire anche istruzione, in modo da rendere più agevole a tutti l’accesso al web.
In poco tempo il web iniziò a diffondersi anche al di fuori del CERN e già verso il 1995 l’adozione pubblica iniziava a essere significativa, con una vera esplosione nella seconda metà degli anni ’90, portando tra l’altro alla bolla delle Dot-com[18] con l’inizio del nuovo millennio.
Nonostante la crisi però, l’utilizzo del web continuò a diffondersi, arrivando ai nostri giorni.
Nel corso della sua breve vita, il web non è mai rimasto fermo ma ha continuato a evolversi, attraversando essenzialmente due fasi: quella del web 1.0 e quella del web 2.0, alle quali dovrebbe seguire quella del web 3.0, protagonista di questa lezione, che, come vedremo a breve, è abbastanza ambigua.
3- Web 1.0
La prima fase si estende approssimativamente dal 1991, anno in cui è stato creato il primo sito web, ai primi anni dei 2000.
In questa fase embrionale, il focus era maggiormente sulle potenzialità del concetto di ipertesto e quindi la maggior parte dei contenuti erano semplici pagine web statiche che mettevano a disposizione dei link a delle risorse.
L’architettura era quella client-server e c’era una netta separazione tra chi metteva a disposizione dei contenuti (poche persone) e chi ne fruiva (tante persone).
I fruitori avevano un ruolo estremamente passivo, essendo le possibilità di interazioni con le pagine molto ridotte.
Anche dal punto di vista estetico le pagine erano rudimentali, concentrandosi di più, come appena detto, sul contenuto e le potenzialità degli ipertesti.
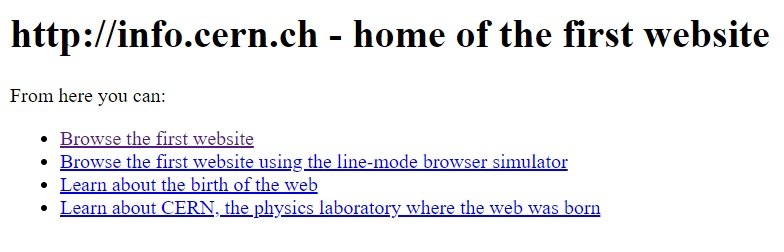
Un esempio che possiamo prendere in considerazione è proprio il primo sito creato info.cern.ch[19], tuttora accessibile e che ha mantenuto lo stile dei primi siti.
Poco per volta si iniziò a prestare più attenzione anche all’aspetto estetico dei siti, in particolare con la nascita di strumenti come il linguaggio di stile CSS (Cascading Style Sheets)[20].
Ovviamente le limitazioni erano anche in linea con i mezzi tecnologici dell’epoca: le pagine dovevano essere leggere, data la lentezza delle connessioni internet.
Riassumendo il punto fondamentale, che è quello che ci interessa maggiormente: per descrivere questa prima era del web, si fa spesso riferimento al paradigma del Web statico, espressione usata in alternativa a web 1.0.
Come suggerisce il nome, si tratta di una paradigma contraddistinto da un’interazione unilaterale tra utenti (client) e fornitori di contenuti (server). L’utente aveva il solo ruolo di fruitore, non poteva produrre contenuti, né modificare lo stato dei siti statici.
I contenuti venivano salvati su dei server e visualizzati dagli utenti, senza subire manipolazioni né lato client, né lato server. Non era quindi necessario l’intervento di programmatori, bastava scrivere i contenuti in HTML e al limite utilizzare il CSS per lo stile.
Nonostante sopravvivano dei siti riconducibili a questo paradigma che, tutt’oggi, offre dei vantaggi quali un’estrema velocità nel servire i contenuti (vista l’assenza di computazioni complesse) e anche nella realizzazione di quest’ultimi, il web per come lo conosciamo è in gran parte appartenente alla seconda era, quella del web 2.0 e quindi riconducibile al paradigma del Web dinamico.
4- Web 2.0
Il termine web 2.0 è stato usato per la prima volta nel 1999 dal consulente informatico Darcy DiNucci in un articolo dal titolo “Fragmented Future”[21], in cui presentava la sua visione del futuro del web, svincolato dal browser su computer e accessibile praticamente da ogni dispositivo: cellulari, televisioni, schermi sulle automobili e via dicendo. Un’intuizione che si è rivelata decisamente corretta.
In seguito all’articolo di DiNucci, l’espressione non venne usata per qualche anno (ricordiamo che vi fu di mezzo la bolla delle dot-com), fino a quando, nel 2002 venne pubblicato il libro Web 2.0: 2003-08 AC (After Crash) The Resurgence of the Internet & E-Commerce[22] [23], in cui si cercava di spiegare che l’esplosione della bolla speculativa non sanciva la morte del web.
Arriviamo così al 2004, anno in cui O’Reilly Media organizzò la prima web 2.0 conference.
In questa pubblicazione[24] del 2005 di Tim O’Reilly si può già leggere una definizione molto dettagliata di web 2.0.
Sul sito del W3C, si trovano documenti riguardanti il web 2.0 risalenti al 2006[25], non troppo distante dalle conferenze di O’Reilly.
È chiaro dunque che per la metà dei 2000 si era già andata a strutturare un’idea di web 2.0 ben definita e, sotto molti punti di vista, contrapposta a quella di web 1.0.
Ma veniamo ai fatti: cosa è cambiato con il web 2.0?A livello tecnologico, non molto.
Certo, la velocità delle connessioni internet è aumentata nel tempo, così come la potenza computazionale dei server, rendendo quindi possibile presentare delle risorse computazionalmente più onerose.
Si sono diffusi i dispositivi mobili, la cui potenza è aumentata esponenzialmente nel corso del tempo.
Si sono evoluti anche i linguaggi utilizzati in ambito web (i già citati HTML e CSS ma anche JavaScript e altri ancora).
Tuttavia, a livello di rete il protocollo a livello applicativo è rimasto HTTP, così come è rimasta valida la suite TCP/IP.
Ad essere cambiata maggiormente è la filosofia con cui si è sviluppato il web.
Se prima la comunicazione era unidirezionale, con il web 2.0 gli utenti non svolgono più il ruolo di semplici client passivi ma partecipano attivamente, creando contenuti e andando a modificare lo stato dei siti web che, per tanto, non sono più statici.
Per questo motivo, se il web 1.0 era basato sul paradigma del web statico, ci si riferisce al web 2.0 come web dinamico.
I contenuti dei siti non sono più semplici pagine statiche ma contenuti generati dinamicamente, ovvero attraverso delle computazioni che richiedono l’utilizzo di linguaggi di programmazione, sia lato server (Java e PHP sono stati tra i più utilizzati ma la lista è lunga) che lato client (JavaScript).
Il web 2.0 vede il passaggio dai siti personali ai blog, in cui chiunque può pubblicare propri contenuti facilmente, senza conoscenze tecniche, e chiunque può commentare o iscriversi.
Nascono le Wiki (Wikipedia è l’esempio più noto), siti in cui gli utenti partecipano alla creazione dell’informazione che viene condivisa.
Nascono i social network, in cui chiunque diventa produttore attivo di contenuti.
Attenzione però, il fatto che la comunicazione sia bidirezionale non vuol dire che venga abbandonato il paradigma client-server e quindi un’architettura centralizzata.
Spesso si è sentito parlare di democratizzazione del mezzo[26] ed è indubbio che un processo di democratizzazione del web sia avvenuto.
Nei primi anni, senz’altro, erano in pochi a potersi permettere un server sul quale ospitare un sito, sia per i costi degli apparati tecnologici, sia per le conoscenze tecniche.
Con l’avvento dei servizi come WordPress, chiunque è in grado di creare un sito con qualche click, per altro con la possibilità di metterlo online gratuitamente, sfruttando i vari web hosting gratuiti (si pensi ad Altervista).
Il processo di democratizzazione tecnologica, del resto, non ha riguardato solo il web ma qualsiasi strumento che ora ha avuto diffusione di massa (gli smartphone, o ancor prima gli stessi computer).
Democratizzazione però non coincide con decentralizzazione.
È vero che su YouTube chiunque può pubblicare contenuti ma questi contenuti saranno immagazzinati nei server di Google, server centralizzati sui quali non abbiamo alcun controllo.
Questo ci porta finalmente al concetto di web3.
5- Web 3.0 o web3
Per prima cosa va specificato che, nonostante si senta utilizzare sia l’espressione web 3.0, sia web3, spesso utilizzati come sinonimi, in realtà si tratta di due concetti diversi, due visioni diverse del futuro del web, riconducibili a due persone.
Da una parte abbiamo il web 3.0 di Tim Berners-Lee, l’inventore del Web, chiamato anche web semantico.
Dall’altra parte abbiamo il concetto di web3 esposto da Gavin Wood, co-fondatore di Ethereum.
L’utilizzo dell’espressione “web semantico” da parte di Lee risale al 1999[27] e in seguito, nel 2001[28], ne diede una definizione più compiuta.
Con questa espressione, Lee fa riferimento a un’evoluzione del web in un ambiente in cui i documenti siano “machine readable” (leggibili dai computer) attraverso l’inserimento di metadati che specifichino il contesto semantico dei documenti stessi.
Lee portò avanti questa visione del futuro del web con il già citato W3C, con l’obiettivo di sviluppare un set di standard a supporto di un web semantico.
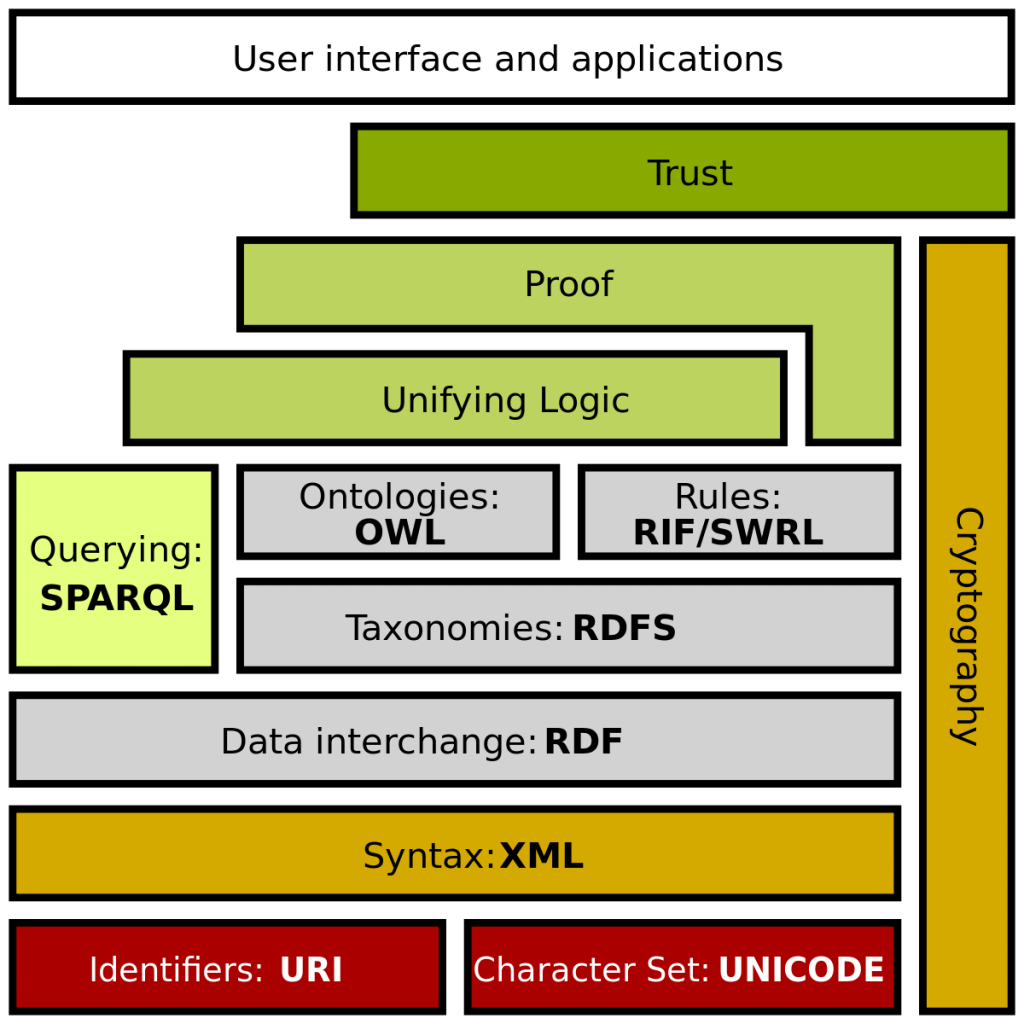
Così, nel corso del tempo, sono nati diversi linguaggi per l’annotazione semantica dei documenti presenti sul web, come RDF[29] e OWL[30].
Sul sito del W3C, si parla di un web of data, il cui scopo principale sarebbe quello di rendere i computer in grado di svolgere lavori più utili[31]: non si tratta semplicemente di rendere i documenti comprensibili dalle macchine ma di sfruttare la loro capacità computazionale, ad esempio, per trarre delle inferenze dai documenti, per sottolineare delle associazioni basate sulla semantica, in tempi molto ridotti rispetto a quelli impiegati da un umano.
Il W3C ha elaborato una Semantic Web Stack, una stack di tool fondamentali per lo sviluppo del web semantico[32].
Per concludere con la visione di Lee, ricollegandoci all’espressione web 3.0, possiamo notare che già nel 2006 veniva utilizzata dal W3C[33].
Arriviamo quindi al concetto di web3 che, come abbiamo detto, è stato introdotto da Gavin Wood nel 2014.
Wood è una delle personalità chiave del mondo crypto/blockchain: tra le tante cose che ha fatto, è co-fondatore di Ethereum, creatore di Polkadot e Kusama e ha inventato il linguaggio di programmazione per smart contract Solidity.
Fin dalle origini di Ethereum, Wood ha sempre parlato di web3, la sua visione del futuro del web, che non ha molto a che fare con il web semantico di Lee ma è piuttosto incentrata sulla tecnologia blockchain e su una filosofia che fa della decentralizzazione il cavallo di battaglia.

Citando direttamente il libro Mastering Ethereum[34], di cui Wood è co-autore, possiamo proporre una prima, semplice, definizione di web3: “La terza versione del web. Proposta inizialmente dal Dr. Gavin Wood, web3 rappresenta una nuova visione e focus per le applicazioni web: dalle applicazioni controllate e gestite centralmente, ad applicazioni costruire su protocolli decentralizzati”.
Sul sito di Ethereum si legge che “la premessa del ‘web 3.0’ è stata coniata dal co-fondatore di Ethereum Gavin Wood poco dopo aver lanciato Ethereum nel 2014. Gavin ha formulato una soluzione al problema molto sentito da molti crypto early adopters: il web richiedeva troppa fiducia”[35].
Al di là del fatto che, come abbiamo visto, l’espressione web 3.0 sia stata coniata da Lee e il W3C, il problema a cui si fa riferimento è quello di un web fortemente centralizzato, in cui grandi compagnie come Facebook, Google, Amazon e via dicendo, monetizzano i dati degli utenti in cambio dei servizi che offrono.
Dobbiamo dunque fidarci di queste compagnie. Certo, ci sono molte leggi a tutela degli utenti del web, però, come insegna la storia, spesso queste leggi sono state infrante.
Il web3, dunque, non è altro che adattare al web la filosofia che sta dietro alla blockchain, alle criptovalute e agli NFT.
Uno degli slogan utilizzati dai creatori di Ethereum è che il web 1.0 era read-only, il web 2.0 era read-write e il web3 sarà read-write-own.
Riprendiamo l’esempio del video su YouTube: quando pubblico un video, sto effettivamente pubblicando sul web un mio contenuto, tuttavia, il fatto che venga effettivamente riconosciuto come mio ci riporta al concetto di fiducia nei confronti di una piattaforma centralizzata, che possiede il mio contenuto nel suo database.
Il web3, appoggiandosi sulla blockchain per quanto riguarda la conservazione dei dati, si pone come una soluzione trustless, ovvero senza necessità di fiducia verso attori centrali.
Pubblicando il mio video su una blockchain, non è più contenuto in un database centralizzato appartenente a una singola compagnia, ma in un registro distribuito peer-to-peer, cosa che introduce diversi vantaggi, tra cui il più importante è senza dubbio la censorship resistance.
YouTube potrebbe censurare il mio video, se non rispetta le norme imposte da Google, sulla blockchain invece non esiste censura.
Lo user si muoverà nel web3 con un solo account crosspiattaforma, account che dovrebbe essere identificato con un wallet, al quale sono collegati tutti i digital asset posseduti.
Viene introdotto quindi un concetto di identità digitale trasversale, crosspiattaforma, che è uno dei veri punti caldi di tutto ciò che ruota attorno alla blockchain.
Uno dei concetti centrali del web3 è quello di DApp (Decentralized Applications).
In un web decentralizzato, le web apps, ovviamente, non dovranno più essere centralizzate, bensì dovranno anch’esse seguire il paradigma della decentralizzazione.
La questione è piuttosto complicata e spinosa e verrà trattata più dettagliatamente nel prossimo paragrafo.
L’idea di web3 di Wood è senza dubbio affascinante ma si scontra con delle criticità di cui bisogna tenere conto, quando si parla di web3 come del futuro del web.
Lo stesso sito di Ethereum riporta le seguenti problematiche:
- Accessibilità = il costo delle transazioni, su reti come quella di Ethereum, è ancora molto elevato, rendendo la vita difficile agli sviluppatori e limitando l’accesso a chi ha ampie possibilità economiche, rischiando dunque di ritornare verso un paradigma centralizzato;
- User experience = al momento è ancora un mondo complicato che necessita una grande semplificazione per l’user medio, che non ha tempo di leggere manuali, imparare terminologie specifiche e via dicendo;
- Education = legato al punto precedente, è necessario in qualche modo diffondere la cultura del web3, facendola arrivare anche all’user medio;
- Centralized infrastructure = attualmente, il web3 è ancora fortemente centralizzato, perché dipende da grandi compagnie. Insomma, non molto diverso dal web che conosciamo tutti.
Chiudiamo questo paragrafo con un accenno a ciò che viene detto riguardo al web3 dalla Web3 Foundation[36], compagnia fondata nientemeno che da Gavin Wood, e che ha lo scopo di promuovere e sviluppare tutti gli strumenti necessari al web3, non diversamente da ciò che è stato il W3C per il web in generale.

Questa è la stack di tecnologie indicata dalla fondazione per lo sviluppo del web3, divisa in 5 layer (in una struttura che può ricordare il modello OSI) che non approfondiremo in questa lezione, per evitare di allungare troppo il discorso.
Sul sito, della fondazione, di cui trovate il link nelle note, potete leggere una breve descrizione di ognuno dei tasselli che compongono la web3 tech stack.
6- DApps vs web apps tradizionali
Le DApps sono il centro attorno a cui ruota tutto ciò che riguarda il web3. Ma cosa sono e come funzionano?
Abbiamo già detto che DApp sta per Decentralized Application e fa riferimento ad applicazioni web la cui architettura è decentralizzata, a differenza del modello standard per le applicazioni web: l’architettura client-server.
Per capire pienamente la portata innovativa delle DApps, bisogna prima avere un’idea di come le cose sono funzionate finora.

L’architettura client-server è composta da due tipologie di attori:
- I server = sono coloro che forniscono servizi sul web, pensiamo ad esempio a un sito come Google.
- I client = sono coloro che usufruiscono dei servizi offerti dai server, accedendovi, nella maggior parte dei casi, tramite l’utilizzo di browser.
Abbiamo già visto che la comunicazione tra client e server è diventata bidirezionale con il passaggio al web 2.0 ma, come già detto, un’architettura di questo tipo resta totalmente centralizzata.
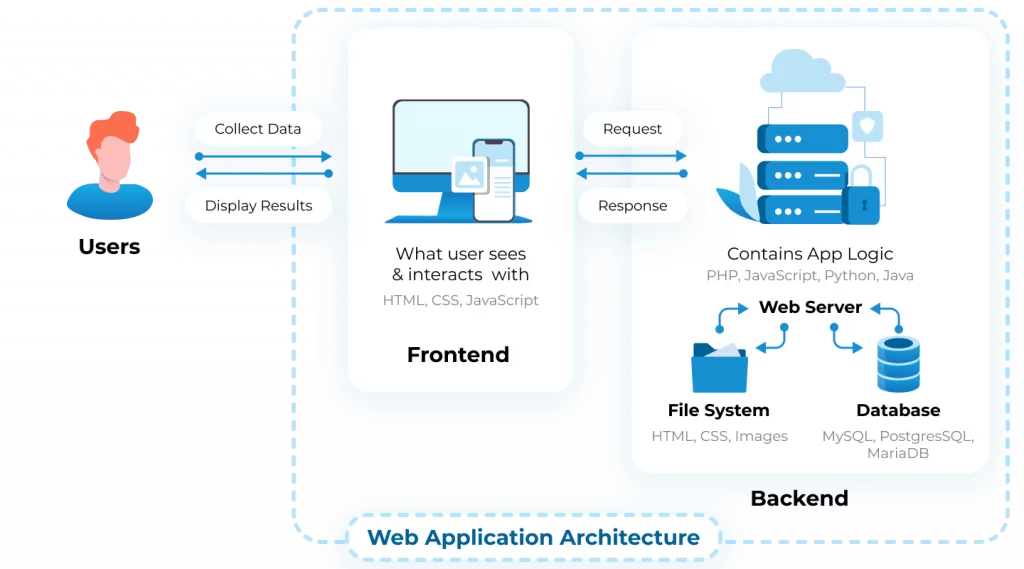
Vediamo ora come funziona una web app.
Semplificando, possiamo dividere una web app in 3 componenti principali:
- Frontend = è la parte che si occupa della visualizzazione, delle interfacce con cui interagiranno gli utenti;
- Backend = è la parte che si occupa di manipolare i dati del database e presentarli al frontend ma anche di ricevere i dati inviati dagli user, attraverso il frontend, e comunicarli al database. Solitamente si indicano queste operazioni come application logic.
- Database = è la parte che si occupa della persistenza dei dati, dunque di tenere in memoria i dati e renderli accessibili al backend.
Questo schema semplifica di molto la struttura di una web app, ci sarebbero altri aspetti di cui tenere conto, come ad esempio il DNS, ovvero il Domain Name Service, il sistema utilizzato per assegnare dei nomi ai nodi della rete, in modo da renderli più comprensibili agli esseri umani rispetto all’utilizzo degli indirizzi IP (stringhe di numeri separati da punti che identificano i nodi di una rete).
Insomma, è ciò che ci permette di cercare sul browser “google.com” al posto di “142.251.209.14”.
Possiamo vederla in questo modo: è più facile ricordare il nome e il numero di una via piuttosto che le coordinate geografiche corrispondenti a quell’indirizzo.
Quando noi scriviamo il nome di un sito su un browser, vengono interrogati dei server speciali, chiamati “root servers”, che contengono le tabelle di associazione tra i nomi e gli indirizzi IP corrispondenti.
La gestione di questo sistema di nomenclatura è in mano all’ICANN (Internet Corporation for Assigned Names and Numbers)[37], istituto fondato il 18 settembre 1998, che si occupa di assegnare gli indirizzi IP e appunto di gestire il sistema dei nomi dei domini di primo livello.
Le tabelle di associazione tra i nomi e gli IP sono contenute in 13 “root server” i cui indirizzi sono indicati in questa pagina[38].

Nel tempo sono nati sistemi di nomi alternativi, soprattutto per ragioni politiche, visto che il sistema appena descritto è fortemente centralizzato.
Tutta questa premessa ci è utile per comprendere a pieno il concetto di DApp.
Spesso infatti, si fraintende il significato di DApp (per ignoranza o in mala fede), pensando che una DApp sia semplicemente una web app che sposta parte della business logic (quindi del backend) su smart contract.
In realtà non è così facile perché il paradigma della decentralizzazione dovrebbe essere applicato a ogni aspetto di una web app, per poterla considerare a tutti gli effetti una DApp e, al momento, sono pochi i casi in cui ciò avviene.
Questo è uno dei motivi per cui molti restano scettici riguardo al web3 e alle DApp, parlando di buzzwords e di hype creato attorno a dei concetti che, nella pratica, sono ancora molto lontani dal concretizzarsi.
Prendiamo il caso di Kevin Werbach[39], accademico e businessman, nonché autore del libro The Blockchain and the New Architecture of Trust, che ha sottolineato come molte delle soluzioni che si spacciano come appartenenti al web3, in realtà non sono decentralizzate come potrebbe sembrare, mentre quelle effettivamente decentralizzate faticano a scalare[40].
O ancora, Moxie Marlinspike[41], creatore di Signal, che ha sollevato ulteriori dubbi sull’effettiva decentralizzazione del web3, sottolineando come l’ecosistema del web3 sia attualmente dominato da poche compagnie, esattamente come è stato per il web finora.
Per non parlare poi di tutti i dubbi relativi allo stato delle tecnologie necessarie per un web3 realmente scalabile[42].
Insomma, gli interrogativi sono diversi, non sorprende quindi che, sfruttando questo la disinformazione e questo ambiente caotico, molti cerchino di sfruttare il trend del web3, spacciando per DApp applicazioni normalissime.
Per capire cosa sia una vera DApp, prendiamo ancora una volta come riferimento il libro Mastering Ethereum[43], co-scritto da Gavin Wood.
Nel libro viene specificato come l’idea di DApp fosse nata già alla nascita di Ethereum e come i creatori non volessero limitarsi a degli smart contract ma reinventare il web.
Viene poi spiegato come una DApp sia un’applicazione che è prevalentemente o totalmente decentralizzata e che la decentralizzazione riguarda i seguenti ambiti:
- Backend
- Frontend
- Data storage
- Message communications
- Name resolution
Ad eccezione delle message communications, abbiamo visto come funzionano tutti gli altri aspetti in una web app standard, vediamo ora come funzionano in una DApp.

Partiamo dagli smart contract: costituiscono idealmente il backend della DApp, la business logic. Elaborano i dati persistenti, li inviano al frontend e viceversa.
Già qui veniamo in contro a un primo problema: pubblicare smart contract costa gas (nel caso di Ethereum), così come costa gas far eseguire le funzioni contenute all’interno degli smart contract.
Più potenza di calcolo è richiesta, più costerà l’esecuzione, cosa che limita molto le operazioni possibili.
Vi è poi da considerare che uno smart contract, una volta pubblicato, è immutabile e quindi, nel caso fosse necessario cambiare la logica al suo interno, si renderebbe necessario creare un nuovo contratto, sostenendo di nuovo le spese di pubblicazione (anche se, in realtà, ci sono dei metodi che, attraverso dei contratti proxy, facilitano questo processo).
Il frontend di una DApp può usare tecnologie web standard (HTML, CSS, JavaScript, ecc.).
Bisognerà utilizzare delle apposite librerie per interfacciarsi con gli smart contract (web3.js[44] per JavaScript).
I client interagiranno con l’applicazione attraverso l’utilizzo di browser wallet come MetaMask.
Sorge spontanea una domanda: dove verranno messi i file che costituiscono il frontend della DApp?
Se venissero messi su un server, si ritornerebbe alla centralizzazione.
Arriviamo dunque al problema del data storage: le web app tradizionali, come già detto, utilizzano database centralizzati per i dati e il file system dei server per i file.
Nonostante gli smart contract diano la possibilità di tenere dati in memoria, non sono gli strumenti adatti per immagazzinare grandi quantità di dati (le blockchain hanno spesso una dimensione limitata dei blocchi, per evitare di far crescere eccessivamente il registro, cosa che comporterebbe molti problemi, a partire dalla scalabilità).
Bisogna quindi ricorrere a un data storage decentralizzato, ci sono diverse soluzioni, tra le quali troviamo:
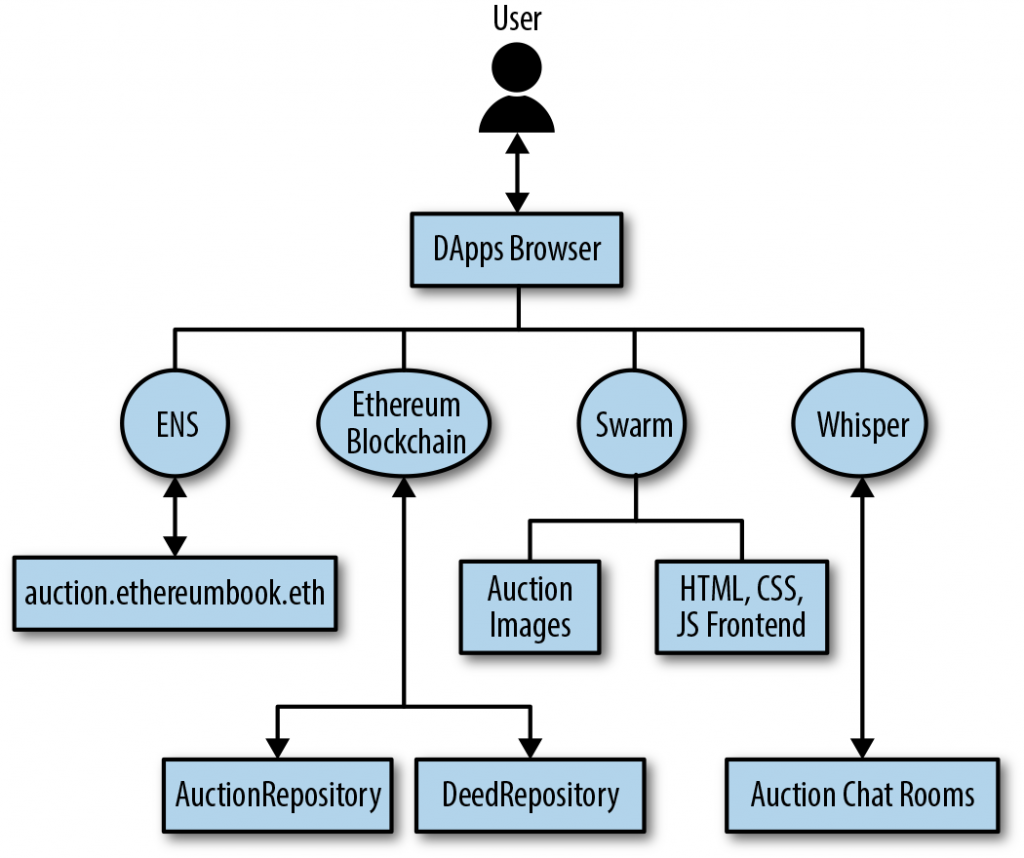
- IPFS (Internet-Planetary File System)[45] = un sistema di storage che distribuisce i dati tra i nodi di una rete P2P. Ogni file ha un hash che lo identifica univocamente su tutta la rete;
- Swarm[46] = storage system P2P, creato dalla Ethereum Foundation. Anche in questo caso, ai file viene associato un hash come identificatore universale.
Swarm fa parte di una suite di tools chiamata Go-Ethereum[47], sviluppata apposta per costruire DApps.
Sarà quindi necessario utilizzare Swarm (o IPFS) per i file necessari al frontend delle DApps.
Senza soffermarci troppo su questo punto, un altro aspetto importante delle applicazioni è la possibilità di scambiare messaggi tra applicazioni. La GO-Ethereum suite propone un tool anche per questo: Whisper[48].
Arriviamo in fine al sistema di naming. Abbiamo visto come funzionano i DNS delle applicazioni tradizionali e abbiamo sottolineato come si tratti di un sistema fortemente centralizzato.
In ambito web3, vi sono delle soluzioni decentralizzate, come l’ENS (Ethereum Name Service)[49] che in Mastering Ethereum viene descritto come una vera e propria DApp utile per costruire altre DApp.
Una DApp, dunque, deve essere totalmente (o quasi totalmente) decentralizzata, in modo da non avere un’autorità centrale e central points of failure.
Si capisce dunque quanto sia complicato costruire una DApp e quali siano le problematiche che ciò comporta.
Quando sentiamo parlare di DApp, cerchiamo di andare oltre agli smart contract, poniamoci queste domande:
- Il frontend sta su un server ed è quindi centralizzato?
- Dove vengono salvati i dati?
- Qual il sistema di naming impiegato?
Sulla base di queste domande, potremo farci un’idea più chiara riguardo all’effettiva decentralizzazione di un’applicazione.
7- Conclusioni
In conclusione, dovremmo ora avere ben chiari i concetti di web3 e DApp e conoscerne sia gli aspetti positivi e la portata innovativa, sia gli aspetti critici e le limitazioni.
Tiriamo velocemente le somme con una lista di pro e contro.
Pro
- Decentralizzazione del web e delle applicazioni
- Resistenti alla censura
- Ognuno è realmente padrone dei propri contenuti
- Identità digitale univoca e crosspiattaforma
Contro
- Problemi di scalabilità
- Si può parlare di reale decentralizzazione se ci sono comunque poche grandi compagnie a dominare l’ecosistema web3?
- Limitazioni intrinseche delle tecnologie necessarie al web3
Note:
[1] https://www.cnbc.com/2021/12/20/elon-musk-web3-seems-more-marketing-buzzword-than-reality-right-now.html
[2] https://it.wikipedia.org/wiki/Modello_OSI
[3] https://it.wikipedia.org/wiki/Organizzazione_internazionale_per_la_normazione
[4] https://en.wikipedia.org/wiki/Internet_protocol_suite
[5] https://developer.mozilla.org/en-US/docs/Web/HTTP
[7] https://it.wikipedia.org/wiki/ARPANET
[8] https://en.wikipedia.org/wiki/MILNET
[9] https://en.wikipedia.org/wiki/NIPRNet
[10] https://it.wikipedia.org/wiki/Ipertesto
[11] https://en.wikipedia.org/wiki/ENQUIRE
[12] https://en.wikipedia.org/wiki/Domain_Name_System
[13] https://www.w3.org/History/1989/proposal.html
[14] https://en.wikipedia.org/wiki/Uniform_Resource_Identifier
[15] https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web/HTML_basics
[18] https://it.wikipedia.org/wiki/Bolla_delle_dot-com
[20] https://developer.mozilla.org/en-US/docs/Web/CSS?retiredLocale=it
[21] http://darcyd.com/fragmented_future.pdf
[22] https://www.researchgate.net/publication/266672416_Web_20_the_origin_of_the_word_that_has_changed_the_way_we_understand_public_relations
[23] https://www.amazon.com/Web-2-0-Resurgence-Internet-Commerce/dp/1587622009
[24] https://www.oreilly.com/pub/a/web2/archive/what-is-web-20.html
[25] https://www.w3.org/WAI/PF/roadmap/DHTMLRoadmap040506.html
[26] http://www.paulgraham.com/web20.html
[27] https://archive.org/details/isbn_9780062515872/mode/2up
[28] https://web.archive.org/web/20171010210556/https://pdfs.semanticscholar.org/566c/1c6bd366b4c9e07fc37eb372771690d5ba31.pdf
[29] https://en.wikipedia.org/wiki/Resource_Description_Framework
[30] https://en.wikipedia.org/wiki/Web_Ontology_Language
[31] https://www.w3.org/standards/semanticweb/
[32] https://en.wikipedia.org/wiki/Semantic_Web_Stack
[33] https://www.w3.org/2007/Talks/0123-sb-W3CEmergingTech/Overviewp.pdf
[34] https://github.com/ethereumbook/ethereumbook
[35] https://ethereum.org/en/web3/#web3
[38] https://it.wikipedia.org/wiki/Root_nameserver
[39] https://en.wikipedia.org/wiki/Kevin_Werbach
[40] https://techcrunch.com/2021/12/14/the-irrational-exuberance-of-web3/?guccounter=1&guce_referrer=aHR0cHM6Ly9lbi53aWtpcGVkaWEub3JnLw&guce_referrer_sig=AQAAAEZFo9aqlvsTq1uMMXRn8MYWjKwRpaPc76ethmyaFRoxW6mrSrhGLe9b-ZfzHQvMDrCmFYajEWdB5Pq3d-cghcl1A36FcRFTDJSwl9E_IO8-pGrdJpPqD5x9uytT52AvILvLfXOAkfGf-7h3RiKvjIdzsOTKuYNljw8sbbI6s3jx
[41] https://en.wikipedia.org/wiki/Moxie_Marlinspike
[42] https://decrypt.co/100781/were-ready-for-the-metaverse-but-the-technology-is-not-heres-why
[43] https://github.com/ethereumbook/ethereumbook/blob/develop/12dapps.asciidoc
[44] https://web3js.readthedocs.io/en/v1.7.3/
[46] https://api.gateway.ethswarm.org/bzz/swarm.eth/
[47] https://geth.ethereum.org/