More and more often we hear about web3, in relation to blockchain (Ethereum in particular), smart contracts and the metaverse.
There is a lot of confusion, between those who talk about web3 as the future of the web, those who misuse the term DApp, and those who downplay it (Elon Musk
So let us try to bring order by explaining what expressions such as web3, web 3.0 and DApp mean.
In this lecture we will trace the history of the Web, so as to better understand what web3 is and what, at least in intention, its innovative scope is.
1- The Internet and the Web
Let’s clarify a fundamental point right away: the Web and the Internet are two different things; they are not synonymous.
The Internet is a global system of computer networks interconnected through the use of a set of protocols.
It is customary in computer science to use a conceptual model to describe telecommunications systems; this is the Open Systems Interconnection ( OSI) model
The OSI model establishes standards for the logical architecture of a network through a structure consisting of seven layers or layers (in English “layers”) that follow a hierarchical order.
Without going into detail, suffice it to say that each layer uses a set of communication protocols.
A communication protocol is nothing more than a set of formally established rules that govern how entities communicate with each other.
Think, for example, of when we answer a call and say, “Hello, who is this?” We can see this as an extreme simplification of a communication protocol.
By saying this phrase, we let the other party know that we have answered the call and are ready to start the conversation.
Similarly, the various entities that make up a network need rules that unambiguously define how they communicate with each other.
| Layer | Name | Protocols |
|---|---|---|
| 7 | Application Layer | HTTP, FTP, DNS, SNMP, Telnet |
| 6 | Presentation Layer | SSL, TLS |
| 5 | Session Layer | NetBIOS, PPT |
| 4 | Transport Layer | TCP, UDP |
| 3 | Network Layer | IP, ARP, ICMP, IPSec |
| 2 | Data Link Layer | PPP, ATM, Ethernet |
| 1 | Physical Layer | Ethernet, USB, Bluetooth, IEEE802.11 |
Thus in the OSI model we have 7 layers, in each of which specific protocols are used.
Another commonly used model is the Internet protocol suite
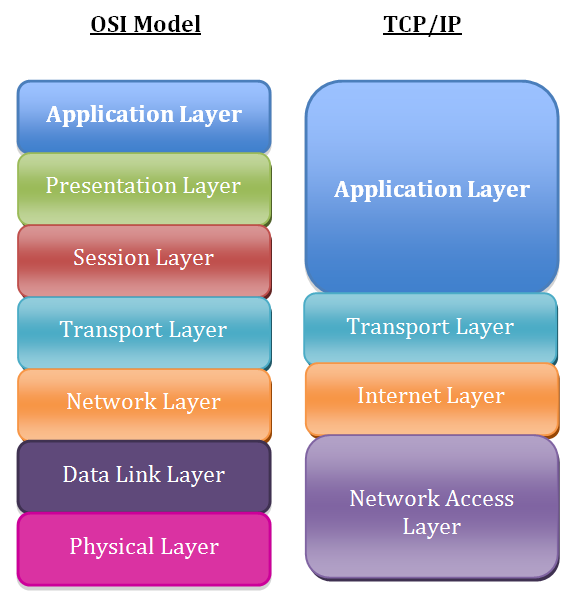
By World Wide Web (abbreviated Web), we mean one of the main services of the Internet.
The Web is based on the Hypertext Transfer Protocol ( HTTP )
In the Application Layer we thus find, as the name suggests, several applications of the internet, one of which is the web.

2- History of the internet and the web
Having made this fundamental distinction between the Internet and the Web, let us quickly review the history of the latter, which, of course, is intertwined with that of the Internet.
The history of the internet goes back much further than that of the web.
In the 1960s, at the height of the Cold War, DARPA
ARPAnet, the ancestor of the Internet we are all familiar with, was then developed for military purposes and later began to be developed in academia as well.
As early as the second half of the 1970s, the word Internet began to be used, and with the standardization of the Internet Protocol Suite in 1982, the number of interconnected networks began to grow.
By 1983, what by then had become for all intents and purposes the Internet of today had totally lost its initial military purpose, which is why the military section isolated itself and MILNET was born
Once it separated from MILNET, therefore, the Internet continued on its way, which brings us up to today.
Parallel to the development of the Internet, in the 1980s, the conditions were being prepared for the birth of the World Wide Web.

The birth of the Web is closely linked to Tim Berners-Lee, a British computer scientist born in 1955.
Lee put together concepts and technologies that already existed:
- Internet and TCP/IP protocols
- The concept of hypertext = a set of documents linked together through keywords that allow nonlinear reading, that is, jumping from one document to another by following links
[10] .
In 1980, while working at CERN in Geneva, he created ENQUIRE
Meanwhile, with the spread of the Internet during the 1980s, many people realized the need to have a system for finding and organizing information scattered among the web.
Thus, in 1985, the Domain Name System (DNS) was born
Continuing to work on his project, Lee arrived at a first concrete proposal in 1989, with a document called Information Management: A Proposal
The proposed system was still called Mesh, although the word “web” was already being used.
Lee and his team developed the toolset that the Web still uses today, such as the idea of URIs (Universal Resource Identifiers)
In 1994 Lee founded the World Wide Web Consortium (W3C)
Before long the web began to spread outside CERN, and by about 1995 public adoption was already beginning to be significant, with a real explosion in the second half of the 1990s, leading to, among other things, the Dot-com bubble
Despite the crisis, however, the use of the Web continued to spread, reaching the present day.
During its short life, the web has never stood still but has continued to evolve, essentially going through two phases: web 1.0 and web 2.0, which should be followed by web 3.0, the protagonist of this lecture, which, as we will see shortly, is quite ambiguous.
3- Web 1.0
The first phase extends roughly from 1991, when the first website was created, to the early 2000s.
In this embryonic phase, the focus was more on the potential of the hypertext concept, and so most content was simply static web pages that provided links to resources.
The architecture was client-server, and there was a clear separation between those who made content available (a few people) and those who used it (many people).
The users had an extremely passive role, the possibilities for interactions with the pages being very small.
Aesthetically, the pages were also rudimentary, focusing more, as just mentioned, on the content and potential of hypertexts.
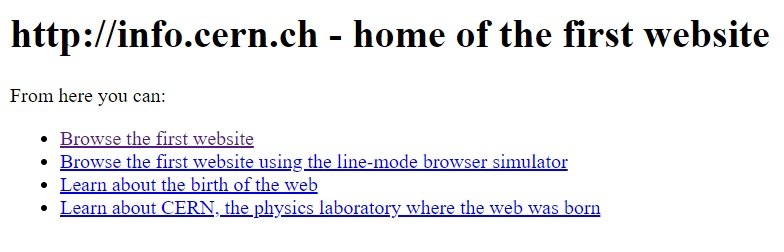
An example we can consider is precisely the first site created info.cern.ch
Little by little, more attention also began to be paid to the aesthetic aspect of the sites, particularly with the emergence of tools such as the CSS (Cascading Style Sheets) style language
Of course, the limitations were also in line with the technological means of the time: pages had to be lightweight, given the slowness of Internet connections.
Summarizing the basic point, which is the one we are most interested in: to describe this early era of the Web, reference is often made to the Static Web paradigm, an expression used as an alternative to Web 1.0.
As the name suggests, this was a paradigm marked by one-sided interaction between users (clients) and content providers (servers). The user had the role of a user only; he could not produce content or change the state of static sites.
Content was saved on servers and displayed by users, without being manipulated on either the client or server side. Thus, programmers were not needed; it was enough to write the content in HTML and at the limit use CSS for styling.
Although there survive sites that can be traced back to this paradigm, which, to this day, offers advantages such as extreme speed in serving content (given the absence of complex computations) and also in the realization of content, the Web as we know it is largely belonging to the second era, that of Web 2.0 and therefore traceable to the dynamic Web paradigm.
4- Web 2.0
The term Web 2.0 was first used in 1999 by computer consultant Darcy DiNucci in an article entitled “Fragmented Future”
Following DiNucci’s article, the expression was not used for a few years (remember that the dot-com bubble was involved), until, in 2002, the book Web 2.0: 2003-08 AC (After Crash) The Resurgence of the Internet & E-Commerce
This brings us to 2004, when O’Reilly Media organized the first Web 2.0 conference.
In this publication
On the W3C website, one can find documents regarding web 2.0 dating back to 2006
It is clear, then, that by the mid-2000s a well-defined and, in many ways, contrasting idea of web 2.0 to web 1.0 had already gone into structure.
But let’s come to the facts: what has changed with web 2.0?On a technological level, not much.
Certainly, the speed of Internet connections has increased over time, as has the computational power of servers, thus making it possible to present computationally more onerous resources.
Mobile devices have become more widespread, and their power has increased exponentially over time.
The languages used in the web have also evolved (the aforementioned HTML and CSS but also JavaScript and others).
However, at the network level the application-level protocol has remained HTTP, as has the TCP/IP suite.
What has changed most is the philosophy by which the Web has developed.
If previously communication was unidirectional, with Web 2.0 users no longer play the role of mere passive clients but actively participate, creating content and going on to change the state of websites, which, therefore, are no longer static.
Therefore, if web 1.0 was based on the static web paradigm, we refer to web 2.0 as dynamic web.
Site content is no longer simply static pages but dynamically generated content, that is, through computations that require the use of programming languages, both server-side (Java and PHP have been among the most widely used but the list is long) and client-side (JavaScript).
Web 2.0 sees the shift from personal sites to blogs, where anyone can post their own content easily, without technical knowledge, and anyone can comment or subscribe.
Wikis are born (Wikipedia is the best known example), sites where users participate in the creation of the information that is shared.
Social networks are born, where anyone becomes an active producer of content.
Be careful, however, the fact that communication is bidirectional does not mean that the client-server paradigm and thus acentralized architecture is abandoned.
We have often heard of democratization of the medium
In the early years, undoubtedly, few people could afford a server on which to host a site, either because of the cost of technological equipment or technical knowledge.
With the advent of services such as WordPress, anyone is able to create a site with a few clicks, for that matter with the possibility of putting it online for free, taking advantage of the various free web hosting (think Altervista).
The process of technological democratization, after all, has affected not only the web but any tool that has now had mass diffusion (smartphones, or even earlier computers themselves).
Democratization, however, does not coincide with decentralization.
It is true that on YouTube anyone can post content but this content will be stored on Google’s servers, centralized servers over which we have no control.
This brings us finally to the concept of web3.
5- Web 3.0 or web3
First, it should be specified that although we hear both the expression web 3.0 and web3 used often as synonyms, in reality these are two different concepts, two different visions of the future of the web, attributable to two people.
On the one hand we have the web 3.0 of Tim Berners-Lee, the inventor of the Web, also called the semantic web.
On the other side we have the concept of web3 expounded by Gavin Wood, co-founder of Ethereum.
Lee’s use of the expression “semantic web” dates back to 1999
By this expression, Lee refers to an evolution of the web into an environment in which documents are “machine readable” through the inclusion of metadata that specifies the semantic context of the documents themselves.
Lee carried forward this vision of the future of the web with the aforementioned W3C, with the goal of developing a set of standards to support a semantic web.
Thus, over time, several languages for semantic annotation of documents on the web have emerged, such as RDF
On the W3C website, there is talk of a web of data, the main purpose of which would be to enable computers to do more useful work
The W3C has developed a Semantic Web Stack, a stack of fundamental tools for the development of the semantic web
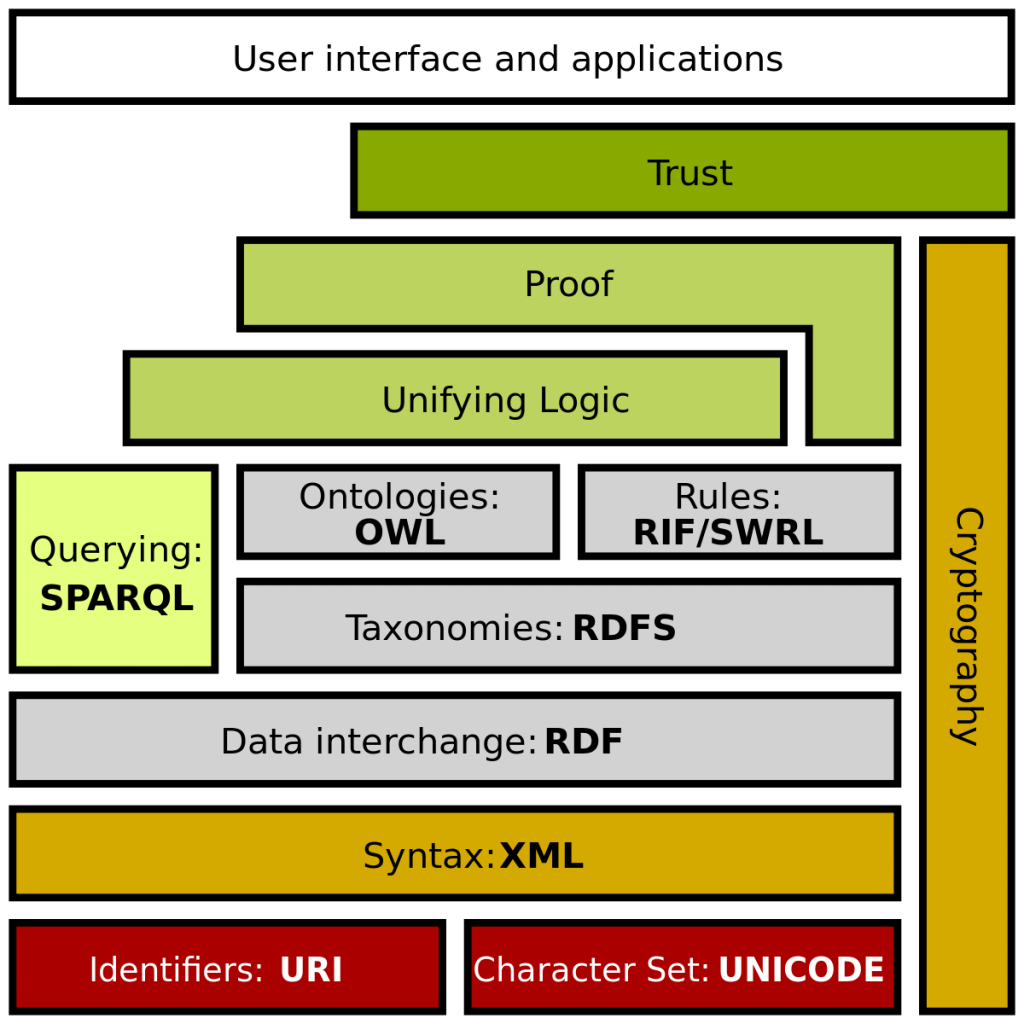
To conclude with Lee’s view, reconnecting with the expression web 3.0, we can note that as early as 2006 it was used by the W3C
We then come to the concept of web3, which, as we mentioned, was introduced by Gavin Wood in 2014.
Wood is one of the key personalities in the crypto/blockchain world: among the many things he has done, he is co-founder of Ethereum, creator of Polkadot and Kusama, and invented the smart contract programming language Solidity.
Since Ethereum’s origins, Wood has always talked about web3, his vision of the future of the web, which has little to do with Lee’s semantic web but is rather focused on blockchain technology and a philosophy that makes decentralization the workhorse.

Quoting directly from the book Mastering Ethereum
Ethereum’s website states that “the premise of ‘web 3.0’ was coined by Ethereum co-founder Gavin Wood shortly after he launched Ethereum in 2014. Gavin formulated a solution to the problem much felt by many crypto early adopters: the web required too much trust.”
Beyond the fact that, as we have seen, the expression web 3.0 was coined by Lee and the W3C, the problem referred to is that of a highly centralized web, where large companies such as Facebook, Google, Amazon and so on, monetize user data in exchange for the services they offer.
We must therefore trust these companies. Of course, there are many laws to protect web users, however, as history teaches, these laws have often been broken.
Web3, then, is nothing more than adapting the philosophy behind blockchain, cryptocurrencies and NFTs to the web.
One of the slogans used by the creators of Ethereum is that web 1.0 was read-only, web 2.0 was read-write, and web3 will be read-write-own.
Let us take the example of the YouTube video again: when I post a video, I am actually posting my own content on the web, however, the fact that it is actually recognized as mine brings us back to the concept of trusting a centralized platform, which owns my content in its database.
The Web3, by relying on the blockchain in terms of data storage, stands as a trustless solution, that is, without the need to trust central actors.
By publishing my video on a blockchain, it is no longer contained in a centralized database belonging to a single company, but in a peer-to-peer distributed ledger, which introduces several advantages, the most important of which is undoubtedly censorship resistance.
YouTube could censor my video if it does not comply with the rules imposed by Google, on the blockchain, on the other hand, there is no censorship.
The user will move around the web3 with only one cross-platform account, an account that should be identified with a wallet, to which all digital assets owned are linked.
Thus, a concept of a cross-, cross-platform digital identity is introduced, which is one of the real hot spots of everything revolving around blockchain.
One of the central concepts of web3 is that of DApps (Decentralized Applications).
In a decentralized web, web apps, of course, will no longer have to be centralized, but will also have to follow the decentralization paradigm.
This issue is rather complicated and thorny and will be discussed in more detail in the next section.
Wood’s idea of web3 is undoubtedly fascinating, but it runs into critical issues that need to be taken into account when talking about web3 as the future of the web.
Ethereum’s own website reports the following issues:
- Accessibility = the cost of transactions, on networks like Ethereum’s, is still very high, making life difficult for developers and limiting access to those with ample economic means, thus risking a return toward a centralized paradigm;
- User experience = at the moment it is still a complicated world that needs a lot of simplification for the average user, who does not have time to read manuals, learn specific terminologies and so on;
- Education = related to the previous point, there is a need to somehow spread the culture of the Web3, making it reach the average user as well;
- Centralized infrastructure = currently, web3 is still highly centralized, because it depends on large companies. In short, not very different from the web we all know.
Let us close this paragraph with a mention of what is said about web3 by the Web3 Foundation

This is the stack of technologies indicated by the foundation for the development of web3, divided into 5 layers (in a structure that may be reminiscent of the OSI model), which we will not elaborate on in this lecture, to avoid stretching it too far.
On the site, of the foundation, whose link is in the notes, you can read a brief description of each of the building blocks that make up the web3 tech stack.
6- DApps vs. traditional web apps
DApps are the center around which everything about web3 revolves. But what are they and how do they work?
We have already mentioned that DApp stands for Decentralized Application and refers to web applications whose architecture is decentralized, unlike the standard model for web applications: client-server architecture.
To fully understand the innovative scope of DApps, one must first have an idea of how things have worked so far.

The client-server architecture consists of two types of actors:
- Servers = are those who provide services on the Web, think for example of a site like Google.
- Clients = are those who use the services offered by the servers, accessing them, in most cases, through the use of browsers.
We have already seen that communication between client and server has become bidirectional with the move to Web 2.0, but, as already mentioned, such an architecture remains totally centralized.
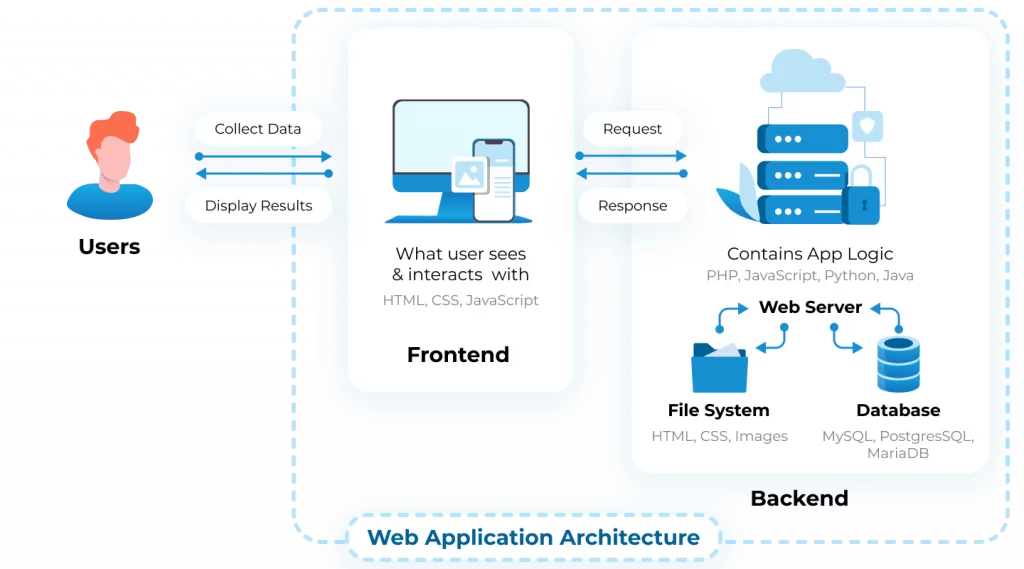
Let us now see how a web app works.
Simplifying, we can divide a web app into 3 main components:
- Frontend = is the part that deals with the visualization, the interfaces that users will interact with;
- Backend = is the part that deals with manipulating database data and presenting it to the frontend but also with receiving data sent by users, through the frontend, and communicating it to the database. We usually refer to these operations as application logic.
- Database = is the part that deals with the persistence of the data, thus keeping the data in memory and making it accessible to the backend.
This schema greatly simplifies the structure of a web app, there would be other aspects to take into account, such as DNS, or Domain Name Service, the system used to assign names to network nodes so that they are more understandable to humans than using IP addresses (strings of numbers separated by dots that identify the nodes on a network).
In short, it is what allows us to search the browser for “google.com” instead of “142.251.209.14.”
We can look at it this way: it is easier to remember the name and number of a street than the geographical coordinates corresponding to that address.
When we type the name of a site on a browser, special servers, called “root servers,” are queried, which contain the association tables between the names and the corresponding IP addresses.
The management of this naming system is in the hands of ICANN (Internet Corporation for Assigned Names and Numbers)
The association tables between names and IPs are contained in 13 “root servers” whose addresses are given on this page

Alternative naming systems have sprung up over time, mainly for political reasons, since the system just described is highly centralized.
All this background is useful for us to fully understand the concept of DApps.
In fact, people often misunderstand the meaning of DApp (either through ignorance or in bad faith), thinking that a DApp is simply a web app that moves some of the business logic (thus the backend) to smart contracts.
In reality, it is not that easy because the decentralization paradigm would have to be applied to every aspect of a web app in order for it to be considered for all intents and purposes a DApp, and at present, there are few cases where this is the case.
This is one of the reasons why many remain skeptical about web3 and DApps, talking about buzzwords and hype created around concepts that, in practice, are still a long way from materializing.
Take the case of Kevin Werbach
Or again, Moxie Marlinspike
Not to mention all the doubts about the state of the technologies needed for a truly scalable web3
In short, the questions are diverse, so it is not surprising that, taking advantage of this misinformation and this chaotic environment, many are trying to exploit the web3 trend by passing off ordinary applications as DApps.
To understand what a real DApp is, let us again take as a reference the book Mastering Ethereum
In the book, it is specified how the idea of DApps was born already at the birth of Ethereum and how the creators did not want to limit themselves to smart contracts but to reinvent the web.
It is then explained how a DApp is an application that is predominantly or fully decentralized and that decentralization covers the following areas:
- Backend
- Frontend
- Data storage
- Message communications
- Name resolution
With the exception of message communications, we have seen how all other aspects work in a standard web app, let us now see how they work in a DApp.

Let’s start with smart contracts: they ideally form the backend of the DApp, the business logic. They process persistent data, send it to the frontend and vice versa.
Already here we come up against a first problem: publishing smart contracts costs gas (in the case of Ethereum), just as it costs gas to run the functions contained within the smart contracts.
The more computing power required, the more it will cost to execute, which greatly limits the possible operations.
There is also the fact that a smart contract, once published, is immutable, and therefore, should it be necessary to change the logic within it, it would be necessary to create a new contract, again incurring the expense of publication (although, in fact, there are methods that, through proxy contracts, facilitate this process).
The frontend of a DApp can use standard web technologies (HTML, CSS, JavaScript, etc.).
Special libraries will need to be used to interface with smart contracts (web3.js
Clients will interact with the application through the use of browser wallets such as MetaMask.
A question arises: where will the files that make up the DApp frontend be put?
If they were put on a server, it would revert to centralization.
So we come to the problem of data storage: traditional web apps, as mentioned earlier, use centralized databases for data and the server file system for files.
Although smart contracts give the ability to hold data in memory, they are not the right tools for storing large amounts of data (blockchains often have a limited block size to avoid overgrowing the ledger, which would lead to many problems, starting with scalability).
Therefore, one must resort to decentralized data storage; there are several solutions, among which we find:
- IPFS (Internet-Planetary File System)
[45] = a storage system that distributes data among nodes in a P2P network. Each file has a hash that uniquely identifies it across the network; - Swarm
[46] = P2P storage system, created by the Ethereum Foundation. Again, files are associated with a hash as a universal identifier.
Swarm is part of a suite of tools called Go-Ethereum
It will therefore be necessary to use Swarm (or IPFS) for the files needed for the frontend of DApps.
Without dwelling too much on this point, another important aspect of DApps is the ability to exchange messages between applications. The GO-Ethereum suite offers a tool for this as well: Whisper
We come finally to the naming system. We have seen how DNS of traditional applications works and we have pointed out that it is a highly centralized system.
In the web3 arena, there are decentralized solutions, such as the ENS (Ethereum Name Service)
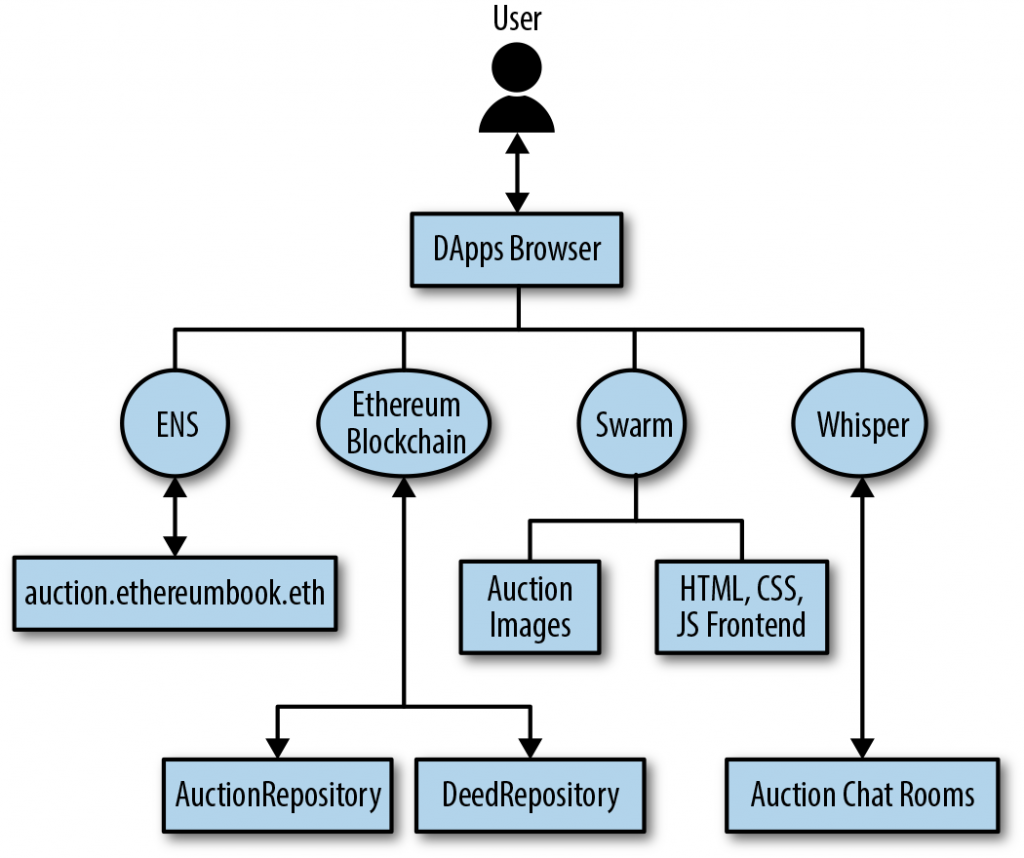
A DApp, therefore, must be totally (or almost totally) decentralized, so that it has no central authority and central points of failure.
One can see, therefore, how complicated it is to build a DApp and what issues this entails.
When we hear about DApps, let’s try to go beyond smart contracts, let’s ask ourselves these questions:
- Does the frontend sit on a server and is it therefore centralized?
- Where is the data stored?
- What is the naming system employed?
Based on these questions, we will be able to get a clearer idea about the actual decentralization of an application.
7- Conclusions
In conclusion, we should now have a clear understanding of web3 and DApp concepts and know both their positive aspects and innovative scope, as well as their critical aspects and limitations.
Let us quickly sum up with a list of pros and cons.
Pros
- Decentralization of the web and applications
- Resistant to censorship
- Everyone is truly in control of their own content
- Unique digital identity and crossplatform
Cons
- Scalability issues
- Can we talk about real decentralization if there are only a few large companies dominating the web3 ecosystem anyway?
- Inherent limitations of the technologies needed for web3
Notes: